Практическая геостатистика – программа консультаций специалистов, занимающихся обработкой материалов и построением карт в области наук о Земле (автор В.Д.Брусницын).
Главная цель в быстром темпе научить желающих программировать, свои частные задачи, вторая – упорядочить свои мысли входе дискуссий. Пока я не освоился, буду писать на форум – заходите, копируйте, думайте. Также по ходу будут рассмотрены вопросы вывода данных в современных ГИС систем, они все разные. Для начала загляните на тему Факторный анализ в геологии, так как я на примере геохимии почв г. Екатеринбурга буду, шаг за шагом показывать как обрабатывать данные и что получается. В начале я хотел замахнуться на весь Урал. Но это не рационально. А эти данные хоть и среднего качества, но МОИ. Я опробовал (копал), я считал, я строил карты и т.д. это было давно (так как был занят мало писал). Даже при стандартном факторном анализе требуется предварительная обработка и подготовка данных, а также последующая. Намерения у меня правильные. Я – Василиус. Не пренебрегайте данным текстом – скопируйте себе смотрите карты и т.д. постараюсь через день или два выдавать по подпрограммке. У меня не очень Интернет, трудно отправлять. Keine Zeit (Not).
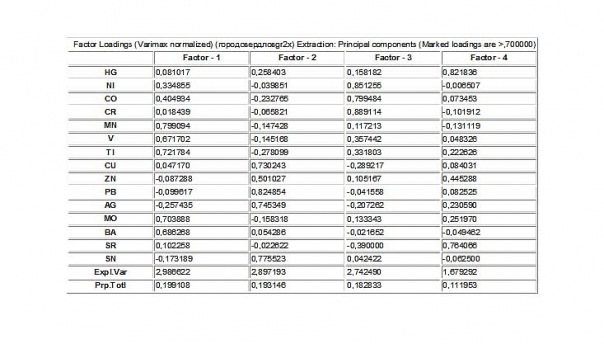
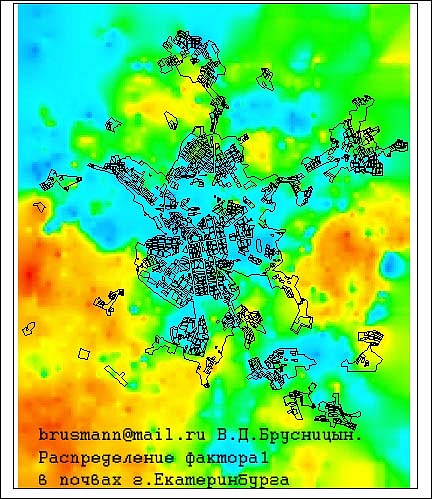
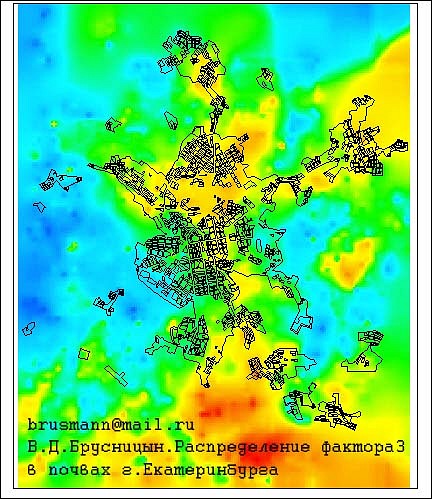
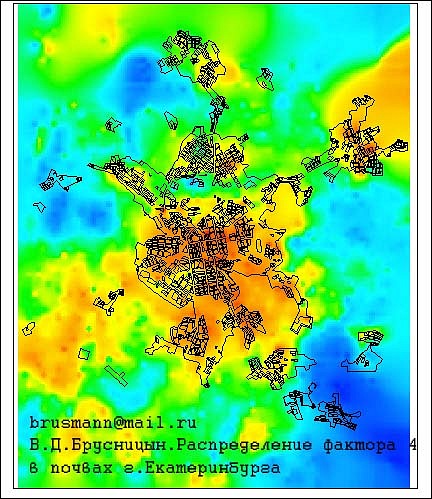
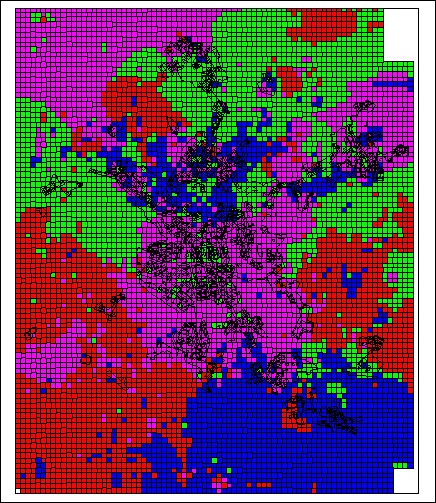
Пример факкарт.
http://cs10506.vkontakte.ru/u98750176/1 ... e56b82.jpghttp://cs10506.vkontakte.ru/u98750176/1 ... 22f973.jpghttp://cs10506.vkontakte.ru/u98750176/1 ... b6a7f7.jpghttp://cs10506.vkontakte.ru/u98750176/1 ... 629131.jpghttp://cs10506.vkontakte.ru/u98750176/1 ... 08da21.jpghttp://cs10506.vkontakte.ru/u98750176/1 ... d18ba3.jpgДальше будет интересней!!!
В практической работе, связанной с компьютерной обработкой материалов в области наук о Земле существует определенные трудности. Многие высококлассные специалисты геологи недостаточно владеют современными методами компьютерной обработки материалов и автоматизированного построения карт различного типа при помощи разнообразных программ. С другой стороны специалисты-информатики не достаточно понимают предмет и объекты исследования в геологии. В настоящее время накоплен огромный материал в цифровом виде: массивы данных, картографические материалы, количество которого постоянно растет. Необходимо эффективное использовать этот материал.
Это основная причина разработки данной программы.
Автор представленной программы имеет многолетний практический опыт полевых и камеральных работ в области гидрогеологии(гидрогеологические и инженерно-геологические условия Ново-Шемурского, Сафьяновского месторождений), геохимии (Урал, Кольский п-ов) и геоэкологии (хим.сотав врд медноколчеданных месторождений Урала, почво-грунты Свердловского промузла и др более мелкие работы по листам 1:200000), программировании (составление программ: КЕМГЕП под руководством Г.А.Вострокнутова 1995-2000, ГЕОКЛАСС самостоятельно 2000-не окончена и др. Будем с сегодняшнего дня продолжать вместе с вами) и автоматизированному посторению различного типа карт(множество гео и гидрохимических карт различных масштабов) .
В программе предпринята попытка разработать системный подход к обработке как аналитических, так и картографических материалов.
Основная цель программы дать главные положения практической статистической обработки материалов и автоматизированной картографии наиболее часто применяемые на практике в геологии. Многие детали, прекрасно изложенные в обширной литературе (смотри краткий список литературы) не приводятся. С учетом важности и наибольшей трудности наибольшее внимание уделено методам классификации (в том числе диагностической).
Общие принципы обработки информации:
Тип обработки и анализа, который может быть осуществлен с данными, определяется шкалой измерений или способом которым наблюдению приписываются численные значения.
Обычно выделяют четыре шкалы измерений:
номинальная шкала - классифицирует две две взаимно исключающие друг друга категории. Например “А”, “Б” или гранит, диорит и тд. Можно сосчитать только количество экземпляров по категориям или “классам”; два класса в пространстве разделяются резкой границей без плавных переходов.
порядковая шкала - позволяет наряду с отнесением наблюдения к определенному классу позволяет определенным образом упорядочивать эти классы. Например, шкала Мооса - 10 - делений но разность между соседними уровнями различна; Применяется при использовании не очень качественных данных (спектральный анализ) и иногда для огрубления данных, так как ряд специалистов считает, что для классификации в геологии следует применять только порядковые данные. В настоящее время при хорошем практическом материале отдается предпочтение арифметическим шкалам. В данной шкале можно выполнять только ограниченное число математических расчетов.
интервальная шкала и шкала отношений (арифметические) почти одинаковы за исключением того, что последняя имеет естественный нуль. В этих шкалах длина последовательных интервалов постоянна. Пример интервальной шкалы - температурная шкала Цельсия, отношений - содержание элемента в различных объектах. Можно выполнять все возможные виды статистических расчетов.
Подготовка данных к обработке
Приведение данных к единообразному виду или к одним единицам измерения, и в первую очередь соответствующим единицам измерения, необходимо для полной автоматизации дальнейшей обработки информации с использованием справочных данных. Наиболее распространенны следующие единицы измерения: мг/кг или г/т; мг/л или мг/дм3; весовые % и др.
В связи с вышесказанным возникает необходимость четкого планирования содержания и единиц измерения данных, содержащихся в справочниках. Четкость и однозначность интерпретации данных, содержащихся в справочниках, определяет успех не только автоматизированной обработки данных, но и получения надежных материалов для работы не связанной со статистической и другой обработкой информации.
Основные операции предварительного преобразований данных:
1. Замена необнаруженных данных (0) на половину чувствительности, фоновые содержания, половину минимума по выборке, на случайные величины в интервале минимум – 0. Решить вопрос о компонентах с отсутствующими данными анализов: NULL.
2. Перемножение данных на 10, логарифмирование возведение в степень и др.
Блок предварительного статистического анализа
1. Блок статистики и корреляции - необходим для автоматического и быстрого анализа данных с обходом и учетом NULLей и 0 и др. При этом исследуется: средние, стандарты другое медианы, тип распределения по величине стандартизированной асимметрии и эксцессу и многие другие показатели
2. Более сложную статистическую обработку, включающую факторный анализ и построение графиков, рекомендуется проводить на программах типа Statisticа, SPSS и др.
Справочно-подготовительный блок
1. Преобразование данных:
Без справочных данных
1.1. Перевод данных в логарифмы, возведение в степень и др. Поводится для приведения к более нормальному виду для дальнейшей обработки, вид преобразования принимается в зависимости от результатов предварительной обработки данных и полученных на первом этапе таблиц статистики.
1.2. Приведение к нормальному распределению с параметрами (0, 1) путем автоматического преобразованных (в случае необходимости) данных, расчета среднего (Хj) и стандарта (Sj)
nj
Хj = Хji / nj ,
i=1
1 nj
Sj = ————— S(Xji -SХj)2 ,
n–1 i=1
затем производится нормировка Хji по формуле:
Хji - SХj
Zji = ————————— .
Sj
Zji – нормированные величины
1.3. Преобразование в интервал 0-1 и др.
Обычно выполняется простым делением значения переменной на ее максимальное значение, которое определяется автоматически.
1.4. Ранжирование проводится путем простой сортировки массива и придания переменным рангов (в соответствии с адресом в массиве) вместо значений по возрастанию или убыванию. При наличии одинаковых значений переменной, получаются так называемые связанные ранги, которые в нашем случае вычисляются путем усреднения рангов. При этом вводится поправка Т для расчета коэффициента ранговой корреляции Спирмена; Это очень важная поправка и по недоразумению, часто не публикуется.
mс t3j - tj
Т = S————————;
j=1 12
mс – число групп элементов с совпадающими (усредненными) рангами; tj – объем j группы элементов с совпадающими рангами;
Для расчета коэффициента Кендалла если наблюдается связь t последовательных членов, то все оценки перестановок в этих парах равны 0. Таких пар насчитывается t(t-1). Соответственно сумма а2ij = n*(n-1) - Sum t(t-1), где суммирование производится только для различных комбинаций связей.
T для каждой последовательности - например:
m
Tj = 1/2*∑t(t-1)
l=1
1.5. Группировка выполняется различными и по различным методам. Например:
Zi = E[k*(Xi-Xmin)/(Xmax - Xmin)+0.5],
Где Zi – i-е значение признака в шкале порядка; E[а] – целая часть числа а; к- число градаций (классов) порядка; Xi, Xmin, Xmax - i-е, минимальное и максимальное значения признака в исходной шкале.
Со справочными данными
1.6. Расчет коэффициентов концентраций и суммирующего коэффициента например Zc.
Значения Zc вычисляются в соответствии с разработанной Ю.Е.Саетом и др. методикой (Методические, 1992; Burenkov E.S. et al. 1991) в каждой пробе вычисляются значения Zc по формуле:
n
Zc=∑Кk-(n-1)), где
i=1
С
Кk = ------;
Ck
С - содержание элемента в пробе; Ck - кларковое (фоновое) содержание элемента,; Кk - коэффициент концентрации элемента пробе; n - число слагаемых элементов со значениями Кk≥ 1.
1.7. Расчет баллов по Вострокнутову Г.А.(хитрая нормировка (группировка – смотри формулу выше) с учетом рудных уровней содержаний) и или др. Ка.
lgCji - lgCкj
Бji = 10 —————————————— ,
lgCрj - lgCкj
где Сji, Скj, Срj - наблюдаемые в i пробе, кларковые (к) и рудные (р) содержания j элемента.
1.8. Пересчет содержаний в молекулярные.
1.9. Пересчет содержаний в эквивалентные.
1.10. Расчет величины электрохимического потенциала по содержаниям окислов или минералов в породах.
1.11. Пересчет содержаний, выраженных в эквивалентных и молекулярных формах в эквивалент-процентную форму для построения треугольных диаграмм по различным типам данных (замкнутая система по тройкам = 100%)- ВЕКТОРЫ!.
1.12. Пересчет нормативный петрохимический например CIPW.
1.13. Другие показатели возникшие при практической деятельности.
Обзор статистического описания мер связи между элементами или объектами систем
Меры сходства и расстояния
Принято различать меры на две категории – сопряжения признаков и сходства или расстояния.
Коэффициенты сопряжения признаков
В арифметической шкале
Коэффициент корреляции (Пирсона)
__ _
1/n*SXik Xjk - Xik Xjk
Rs = -----------------,
SkSl __ __
Где Xik Xjk – значения признаков в объекте, Xik Xjk –средние значения признаков, SkSl – стандартные отклонения, вычисляемые повыборке объемом n наблюдений.
Косинус θ – в случае стандартизированных данных равный коэффициенту корреляции (Пирсона)
m
∑ Xik Xjk
k=1
COSθij = ------------
m m _______________________
√ ∑ Xik2 ∑Xjk2
k=1 k=1
В порядковой шкале
Ранговый коэффициент Спирмена. Следует отметить, что коэффициент Спирмена – это просто измененный коэффициент корреляции Пирсона (Смирнов Б.И., 1981). При вычислении обоих коэффициентов по одному и тому же набору рангов получаются абсолютно идентичные результаты. То есть вышеуказанные коэффициенты фактически более универсальны и особой необходимости в вычислении коэффициента Спирмена в настоящее время нет. На это же указывает статья РАНГОВОЙ КОРРЕЛЯЦИИ КОЭФФИЦИЕНТ в современной статистической энциклопедии (Вероятность, 1999) со ссылкой на работу (Daniels H.E., 1948). Однако в связи с тем, что в современных статистических программах, (в том числе КЕМГЕП) этот коэффициент применяется, ниже дается метод его вычисления.
Если обозначить ранги элементов (R) в первом объекте как R1, а во втором – как R2, то rс рассчитывается по формуле:
n
6SR(1)–R(2)]2
rс = 1 - ——————————————.
n(n2-1)
И при наличии связанных рангов rс рассчитывается по формуле:
m
(m3-m)/6 - S (R(maxZc)-Ri)2 – Tк - Tl
j=1
rc = —————————————————————————————————————————
[(m3-m)/6 - 2Tк]1/2 • [[(m3-m)/6 - 2Tl] 1/2
где R1 – ранги элементов в 1 пробе, R2 – ранги элементов во 2 сравниваемой пробе; Tк и Tl – поправки на совпадающие ранги; m – число ранжированных элементов;
Ранговый коэффициент КЕНДАЛЛА rk или (tau - тау). (Кендэл.М. 1975)
Существенно от вышеназванных коэффициентов отличается коэффициент Кендалла – так, как он представляет из себя вероятность нахождения ранжированных данных в однаковом порядке.
Из двух последовательностей рангов по n членов можно выбрать два предмета 1/2*n*(n-1) раз, тогда
S
S1 = ----------
1/2*n*(n-1)
здесь S=P+Q со своим знаком. P и Q положительные и отрицательные суммы (правильный порядок и инверсия). Из этого следуют эквивалентные формулы для вычисления
P-Q 2Q 2P
S1 = ---------- = 1- ---------- = ---------- - 1.
1/2*n*(n-1) 1/2*n*(n-1) 1/2*n*(n-1)
Sjk
S1 = ------------------------------------------
sqrt(1/2*n*(n-1)- Tj)* sqrt(1/2*n*(n-1)- Tk)
Расстояния как меры сходства-различия
Общий вид расстояния (Рожков, 1989)
1 q |Xlj - Xtj|^m
dlt = --- * (∑ ------------)^1/m,
q j=1 Wj
где q - число признаков; l,t = 1,n; j = 1,q; m, Wj - параметры.
d1 при Wj = 1 и m = 2 получается эвклидово или таксономическое расстояние. Сходства противоположны расстояниям - Clt = 1 - dlt и так далее.
Среди многих десятков мер стоит отметить нами уже описанные ранее и их модификации arccos(rlt); 0.5*(1+rlt) - вводятся для исключения отрицательных значений.
Для вычисления по основной формуле признаки могут быть как в порядковой, так и арифметической шкале в зависимости от преобразований. Однако при расчете эвклидова расстояния и ряда других, значения признаков желательно привести к виду при котором их размах укладывается в интервал (0, 1), При этом
При классификации применяются различные методы группировки объектов. Наиболее распространенные из них приведены ниже в таблице
Систематизация методов группировки объектов (Рожков, 1989)
Основания Структура Методы
1. Агломеративные
Отношения Иерархическая 2. Разделительные
сходства 3. Деревьев связи
объектов 4. Разделительные
Неиерархическая 5. Пороговые (гиперсфер)
6. Ординации
Распределе- 7. Координатные
ние признаков Неиерархическая 8.Разделение смеси распределений
9.Оценки однородности
1.Объединение объектов сначала в более мелкие а затем более крупные классы (снизу вверх)- много алгоритмов.
2.Множество объектов делится сверху вниз (вариант алгоритма разработан автором, применялся в практике но не доведен до логического конца).
3.Кратчайший незамкнутый путь - два самых близких объекта. К ним из оставшихся подбирается тот, который ближе к одному из двух! Метод “ближайшего соседа”.
4.Поиск наиболее различающихся объектов, принимаемых за базовые и затем проводится деление на заданное число классов (вариант алгоритма, разработанный автором в программе КЕМГЕП отличается от приведенного выше и заключается в выборе начальной точки классификации).
5.Основаны на введении порога или радиуса сходства (варианты алгоритма, разработанные автором в программе КЕМГЕП отличается от приведенного выше и заключается в выборе начальной точки классификации в первом случае порог задается строго, а во втором вычисляется исходя из строго заданного уровня значимости).
6.Впервые предложен метод - Синоним многомерное шкалирование - метод представления сходства объектов в пространстве меньшей размерности. Вытеснен другими методами? Метод главных координат и компонент <>(факторный анализ) !!! (вариант алгоритма с дополнением кластерного анализа разрабатывается автором, применялся в практике, но не доведен до логического конца. Похожий вариант предложен М.К.Овсовым ).
7.Этот подход разработан для ситуаций, когда нет никакой информации о числе классов на множестве объектов - развитие координатного метода.
8.В основе методов лежит представление о постепенном переходе одного класса в другой, кое-где редко применяется.
9.Перспективный в геологии на основе критерия однородности Д.А.Родионова
Вероятность и математическая статистика: Энциклопедия/ Гл.ред. Ю.В.Прохоров. – М.: Большая Российская энциклопедия, 1999 . 910 с.
Геохимия окружающей среды/Ю.Е. Сает, Б.А. Ревич, Е.П. Янин и др. – М.:Недра, 1990. – 335 с.
Дэвис Дж.С. Статистический анализ данных в геологии / Пер. с англ. В 2 кн. – М.: Недра, 1990. Кн. 1, 319 с., кн. 2, 427 с.
Инструкция по геохимическим методам поисков рудных месторождений. - М.: "Недра", 1983. 191 с.
Йёреског К.Г., Клован Д.И., Реймент Р.А. Геологический факторный анализ / Пер. с англ. – Л.: Недра, 1980. – 217 с.
Кендалл.М, Стюарт А. Статистические выводы и связи. М., Наука, 1973.
Кендэл.М. Ранговые корреляции. М., Статистика, 1975.
Овсов М.К. Интеллектуальная операция структурного анализа геоданных//Изв. Вузов. Геология и разведка, 2000, №1.
Рожков В.А. Почвенная информатика//Всесоюз. Акад. С.-х. Наук им. В.И.Ленина.- М.: Агропромиздат, 1989, 211 с.
Смирнов Б.И. Корреляционные методы при парагенетическом анализе. – М.: Недра, 1981. - 176 с.
Чесалов С.М., Шмагин Б.А. Статистические методы решения гидрогеологических задач на ЭВМ. М.: Недра, 1989. 174 с.
Burenkov E.S. et al. 1991. Geochemical mapping as a method for indicating hazardous environmental situations. Geological Survey of Finland. Special Paper 9. pp. 9-12.
Daniels H.E., “Biometrika”, v. 35 1948.
Howarth R.J. (ed.) Statistics and data analysis in geochemical prospecting. Elsevier Pupl. Co., Amsterdam, 1983 437 p.
Kickert W. J. M. Organization of decision -making. NORTH-HOLLAND PUBLISHING COMPANY-AMSTERDAM, 1980. и др.
Если дочитали – поздравляю. Это начало! (Шутка). Если закосорезили формулы – я в ворде – HTML is not my style.
Подскажите как попасть на страницу автора и где все появляется.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}